
98 posts
Australia
Posted 20 December 2014 - 06:58 AM
kKernel (KiloKernel)
version 0.2
After being inspired by numerous projects such as ccLinux and Leadlined-Kernel, I decided to have a crack at it myself and implement my own version of a kernel.
Screenshots
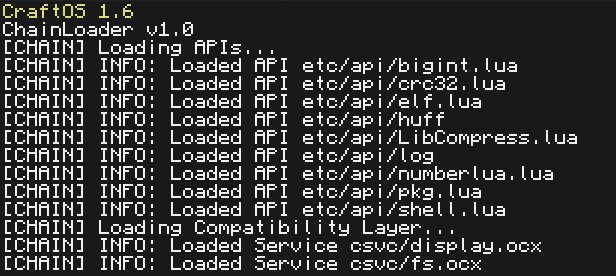
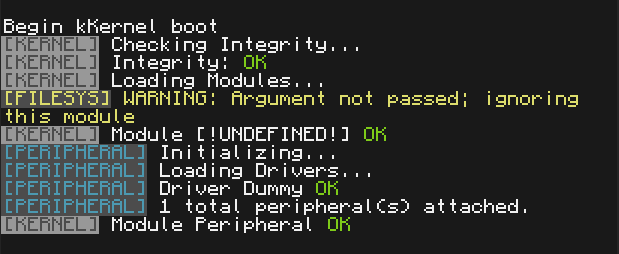
Active Developers:
- Mr. Bateman
- awsumben13
- Adds a "compatibility layer", which does all sorts of amazing things, like allowing non-colour computers/monitors to run colour programs, and workarounds to the infamous LuaJ byte-parsing bug.
- Modular-based system allows you to add your own custom modules, and you can even load modules while the system is operating.
- Peripheral Module allows you to use "drivers", which can run snippets of code when a peripheral is interacted with, such as when it is attached and detached, and even allows you to change how peripheral.wrap works! It gets even better, as it allows you to create virtual peripherals, and even spoof physical peripherals, allowing things such as virtual printers!
- Filesystem Module adds a metadata system, where it saves the last accessed, modified and created time in the '.$MFT' file. Permissions are coming soon.
- ELF and compiled Lua compiler and executor, with a variety of formats and types. Documentation: Soon™
If you want to have a look at more features, documentation and the FAQ, it's all over at the Github Wiki.
You can have a look at the code in it's current state on it's Github Page.
I plan to make an automated installer once I feel okay with the amount of content in it, but right now it's stable enough for releasing here.
Please, post any criticism, comments or suggestions! Bug reports are fine too!
Edited on 24 February 2015 - 11:44 AM









