
767 posts
Posted 08 March 2015 - 08:08 PM
Hello
I've decided to try and make a "compressor" in Lua, with some different algorithms in mind;
Currently im working on an algorythm, where i have the string, and add numbers / Letters corresponding to the amount of that letter etc;
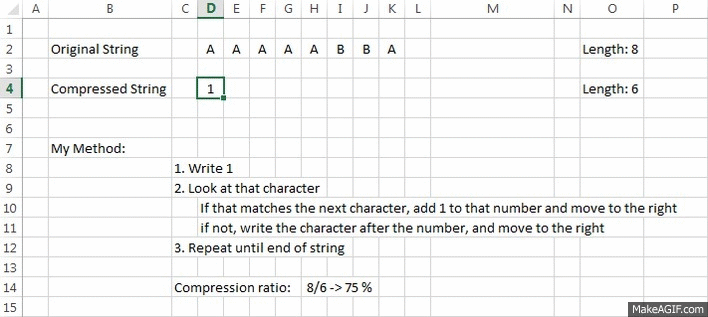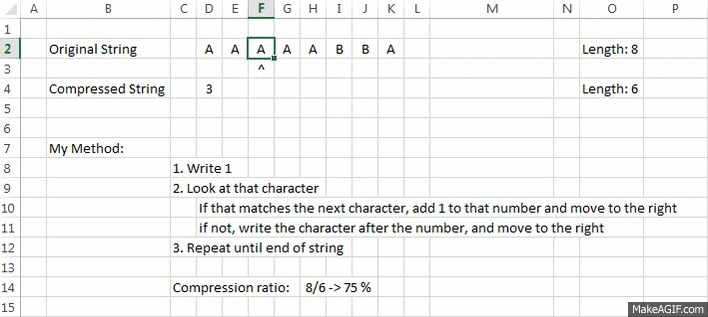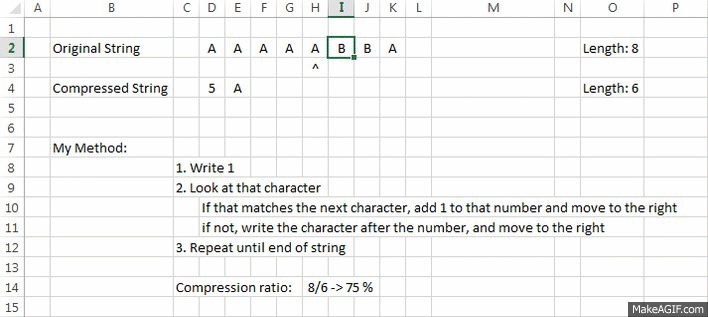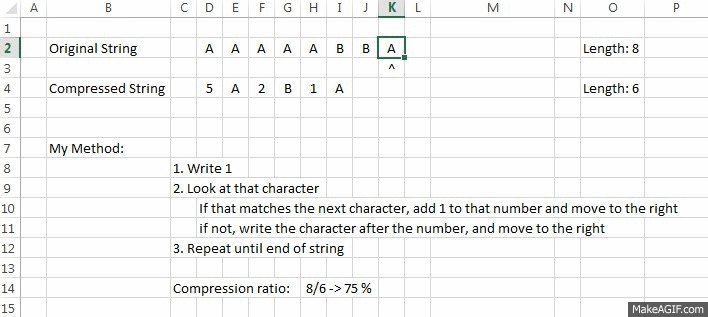
Example:
Explanation:

A small GIF, with a better "vision" of how it works
Currently im making the code, and so far im getting it:
I know it isn't much yet, but i "just" started this project (20 mins ago).
maybe i could make some improvements, but i can't really think of other compression, rather than using a "dictionary" and X pos of that text-field, etc.
So far, i would think this method is pretty good, but if the string does NOT have several "multiple" chars after each other, its going to INCREASE the size instead :(/>
Any suggestions / critics?
Thanks :P/>
I've decided to try and make a "compressor" in Lua, with some different algorithms in mind;
Currently im working on an algorythm, where i have the string, and add numbers / Letters corresponding to the amount of that letter etc;
Example:
OriginalString = "AAAAABBA"
CompressedString = "5A2B1A"
Explanation:
A small GIF, with a better "vision" of how it works
Currently im making the code, and so far im getting it:
--# Implement basic API's
table.size=function(tbl)local Count=0 for k,v in pairs(tbl) do Count=Count+1 end return Count end
--# Main Block --
local Str = 'AAAAABBA' --# Length: 8
local function Compress(Str)
local Length = string.len(Str)
local Output = {}
OutputCurrent = 1
CurrentChar = ''
for I = 1, Length do
local Previous = string.sub(Str, I-1, I-1)
local Current = string.sub(Str, I, I)
local Next = string.sub(Str, I+1, I+1)
if not Output[OutputCurrent] then
Output[OutputCurrent] = {}
end
Output[OutputCurrent]['Amount'] = 1
if Next == Current then
Output[OutputCurrent]['Amount'] = Output[OutputCurrent]['Amount'] + 1
end
Output[OutputCurrent]['Char'] = Current
OutputCurrent = OutputCurrent + 1
end
if table.size(Output) > Length then
print(Str)
return false, Str
end
print(textutils.serialize(Output))
return true, Output
end
Compress(Str)
I know it isn't much yet, but i "just" started this project (20 mins ago).
maybe i could make some improvements, but i can't really think of other compression, rather than using a "dictionary" and X pos of that text-field, etc.
So far, i would think this method is pretty good, but if the string does NOT have several "multiple" chars after each other, its going to INCREASE the size instead :(/>
Any suggestions / critics?
Thanks :P/>
Edited on 08 March 2015 - 07:33 PM

