
30 posts
Posted 31 May 2015 - 08:37 PM
Hello guys,
Here's my take on an archive format for ComputerCraft.
This little script allows you to compress/decompress archives from CLI or from your scripts using the embedded API.
Features:- Compress file(s) and folder(s) in a single archive
- Preserve folder hierarchy
- Compatible with commons images formats
- Reduce file size a little bit
Install: 23QEETmW
pastebin get 23QEETmW zippy
Usage (CLI):Archive creation:
Spoiler
zippy compress /source/folder /my/archive
-- example with short syntax
zippy -c /source/folder /my/archive
Archive extraction:
Spoiler
zippy extract /my/archive /dest/folder
-- example with short syntax
zippy -x /my/archive /dest/folder
zippy.compress ( path, dest )
Spoiler
os.loadAPI('zippy')
zippy.compress('/source/folder', '/my/archive')
zippy.extract ( path, dest )
Spoiler
os.loadAPI('zippy')
zippy.extract('/my/archive', '/dest/folder')

224 posts
Posted 31 May 2015 - 08:59 PM
I don't think deleting certain characters from a file can be called "compression".
But the dictionary concept is a start; though I'm not very familiar with compression techniques.
Anyways, nice lightweight packaging program.
30 posts
Posted 31 May 2015 - 09:17 PM
There should not be any characters deleted in the files after decompression, otherwise it's a bug.
If it's the case, please let me know how to reproduce it.

7083 posts
Location
Tasmania (AU)
Posted 01 June 2015 - 12:40 AM
Just glancing at the paste doesn't make it obvious that there's a bunch of non-ASCII symbols in those "empty"-looking strings. Without trying it, it does look to me like the removed characters should be replaced later. You could call it an example of basic RLE compression.
30 posts
Posted 01 June 2015 - 11:23 AM
Yeah pastebin syntax highlighter has trouble displaying the special chars (they are ascii btw).
You can click on the "raw" link to see where they are, or better: use a decent text editor.
Didn't know about RLE compression, it seems I reinvented this wheel while looking for a way to save a few bytes.
Thanks for teaching me something. :D/>
To explain things a bit:
The compression code looks into files contents to find specific repeating characters (space, TAB, NL, CR).
If the character is repeated more than two times it's replaced with a control char followed by the number of repetition.
I agree this does not results in a high compression ratio but it's something.
Edited on 01 June 2015 - 03:00 PM
30 posts
Posted 01 June 2015 - 02:05 PM
Updated to version 0.4-beta with a few fixes regarding relative path handling.

673 posts
Posted 01 June 2015 - 10:21 PM
Tried it with an NFP file, compressed it fine but decompressing it resulted in a 4 MB file when the original file was only 600 bytes. Spaces in the original file seemed to be elongated by a few hundred thousand times.
After compressing the "zippy" file and extracting it, for some reason some lines of the code were saved to folders..

For my machine, the extracting seems to be a little broken, but it does succeed in decreasing the file size a little.
30 posts
Posted 02 June 2015 - 12:51 AM
Thanks for reporting, update v0.5 should fix the extraction craziness.
Previous archives are not compatible with this update, sorry early beta.
About the folder name containing some code I suspect you to have compressed the zippy script with itself. :D/>
Anyway I have an idea about how to fix it, hopefully coming with the next update adding nested archives feature.
Edited on 01 June 2015 - 10:52 PM
673 posts
Posted 02 June 2015 - 01:29 AM
About the folder name containing some code I suspect you to have compressed the zippy script with itself. :D/>
After compressing the "zippy" file and extracting it
I like how the start of any file compressed with zippy is
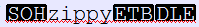
maybe it would be possible to insert the zippy version when archiving in case the format changes and you need to know which version of Zippy to decompress it with.
Kind of like

maybe?
Edited on 01 June 2015 - 11:33 PM
7083 posts
Location
Tasmania (AU)
Posted 02 June 2015 - 01:31 AM
Anyway I have an idea about how to fix it
Does it involve making sure the script doesn't compress itself? Consider what happens if "/" is set as the path to compress - you might also consider setting up exclusions for ROM and disk drive folders.
30 posts
Posted 02 June 2015 - 10:41 AM
I like how the start of any file compressed with zippy is
maybe it would be possible to insert the zippy version when archiving in case the format changes and you need to know which version of Zippy to decompress it with.
Kind of like
maybe?
Oh man, nearly exactly what I had in mind for the header.
I would like to keep the length at 8 bytes so I think of removing ETB in favor of version number.
Something like this:
SOHzippy
1DLEBe sure I will implement this feature before writing the archive format specification.
Does it involve making sure the script doesn't compress itself? Consider what happens if "/" is set as the path to compress - you might also consider setting up exclusions for ROM and disk drive folders.
If you look at the source now you can see the header is stored in a string.
That's what is making zippy do weird things when compressing itself.
Easy fix is to store the header's bytes in a table and construct the header at runtime using a loop.
There's a bunch of assertions making sure files are readable/writeable when they should.
I don't think it is necessary to add exceptions for special folders.
Or maybe provide me an example when it's needed.
Thanks for your interrest, it helps a lot. :)/>
Edited on 02 June 2015 - 10:39 AM
224 posts
Posted 02 June 2015 - 12:23 PM
Just glancing at the paste doesn't make it obvious that there's a bunch of non-ASCII symbols in those "empty"-looking strings. Without trying it, it does look to me like the removed characters should be replaced later. You could call it an example of basic RLE compression.
Yeah pastebin syntax highlighter has trouble displaying the special chars (they are ascii btw).
You can click on the "raw" link to see where they are, or better: use a decent text editor.
Didn't know about RLE compression, it seems I reinvented this wheel while looking for a way to save a few bytes.
Thanks for teaching me something. :D/>
To explain things a bit:
The compression code looks into files contents to find specific repeating characters (space, TAB, NL, CR).
If the character is repeated more than two times it's replaced with a control char followed by the number of repetition.
I agree this does not results in a high compression ratio but it's something.
Ahh I see. Thanks for clearing that up. CC might have some trouble with special characters if you start adding more to the dictionary and moving towards 127 or 128.
30 posts
Posted 02 June 2015 - 12:43 PM
You're welcome.
I'm using this
asciitable to find out which special chars I can use.
Letting away [RS] and [US] because they are allready used in nft image format.
7083 posts
Location
Tasmania (AU)
Posted 02 June 2015 - 01:23 PM
If you're planning on capturing more repeated characters, then my recommendation is "do all of them". Ditch your dictionary and repeated usage of gsub, and instead go through the string
once with sub, comparing each character to the one you read before it.
Or maybe provide me an example when it's needed.
:blink:/> I don't think I can top the example I already gave you. :huh:/>
673 posts
Posted 02 June 2015 - 09:24 PM
Oh man, nearly exactly what I had in mind for the header.
I would like to keep the length at 8 bytes so I think of removing ETB in favor of version number.
Something like this: SOHzippy1DLE
how about
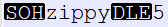
30 posts
Posted 03 June 2015 - 05:43 PM
:blink:/> I don't think I can top the example I already gave you. :huh:/>
Maybe I misunderstood what you mean (non-native english speaker here).
My point is: zippy lets you do what you want but if you try something silly (writing to /rom for example) it will fail with an error message explaining what's wrong.
how about
Yes why not, maybe having a special char at the end of the header make it simpler to parse… or not?
Currently working on the next version which will feature a proper token dictionary.
At this time its compression ratio is between 10 & 30%, not too bad. ^_^/>

2679 posts
Location
You will never find me, muhahahahahaha
Posted 03 June 2015 - 06:07 PM
What if the text is not in english? Or if it ain't a text at all?
30 posts
Posted 03 June 2015 - 06:23 PM
Obviously if there's no text the dict will be empty.
Currently I use gmatch with pattern %w+ to tokenize file contents.
I don't think there's something special to do to handle non english chars.
2679 posts
Location
You will never find me, muhahahahahaha
Posted 03 June 2015 - 06:50 PM
I see. How big will the dictionary be?
30 posts
Posted 03 June 2015 - 09:43 PM
There's no fixed dictionnary size.
Each token is evaluated based on string length and number of occurences.
If it's possible to gain some space for this token then it is added to the dict.
Wait tomorrow, you'll see the updated code. :)/>
Edited on 03 June 2015 - 07:44 PM
2679 posts
Location
You will never find me, muhahahahahaha
Posted 03 June 2015 - 10:13 PM
Oh, so that is how it works. It has nothing to do with languages.
7083 posts
Location
Tasmania (AU)
Posted 04 June 2015 - 12:35 AM
Maybe I misunderstood what you mean (non-native english speaker here).
My point is: zippy lets you do what you want but if you try something silly (writing to /rom for example) it will fail with an error message explaining what's wrong.
Well, let's say you want to archive everything you've put on your computer. You do:
zippy / archive
In addition to getting
your files, zippy will also get:
1) Itself
2) ROM
3) Any disks that're present
Obviously there's no point in getting the first two - compressing these is a waste of disk space. The third is more a matter of taste, but I'd suggest you exclude that too.
30 posts
Posted 04 June 2015 - 01:33 AM
If you run a command like so its purpose is clear and you get what you ask for.
For example, under linux nothing forbids you from doing something crazy like this:
sudo rm -rf /
I agree adding exceptions would make the whole computer backup case easier.
But zippy aims to be an archiver and not a backup tool.
Anyway thanks for explanations, it help me to figure out how the zippy API would be used by such a backup tool.
673 posts
Posted 04 June 2015 - 01:55 AM
If you run a command like so its purpose is clear and you get what you ask for.
For example, under linux nothing forbids you from doing something crazy like this:
sudo rm -rf /
I agree adding exceptions would make the whole computer backup case easier.
But zippy aims to be an archiver and not a backup tool.
Anyway thanks for explanations, it help me to figure out how the zippy API would be used by such a backup tool.
His point is that if you compress the whole drive the rom folder will be saved, which is pointless since the rom folder comes with all computers, therefor shouldn't be archived to save space on the package.
Edited on 03 June 2015 - 11:56 PM
7083 posts
Location
Tasmania (AU)
Posted 04 June 2015 - 02:00 AM
Seems he understands that now, but has decided he doesn't mind.
673 posts
Posted 04 June 2015 - 02:03 AM
Seems he understands that now, but has decided he doesn't mind.
In that case I'm the one misinterpreting the text.
30 posts
Posted 04 June 2015 - 11:29 AM
Ok I changed my mind, it seems that making a backup of the entire computer would be a common use case.
I will probably end up adding a CLI option "backup" to handle this task.
Why not adding exceptions to the (de)compression routine instead?
By hardcoding filesystem assumptions into the compress/extract functions it breaks compatibility with other environments.
For example an OS running a virtual filesystem may have a writeable /rom folder.

2427 posts
Location
UK
Posted 04 June 2015 - 11:49 AM
Have it ask when it's about to compress the /rom folder? I can't imagine someone leaving (AFKing) a CC computer to do stuff, the CC file system is not huge.
30 posts
Posted 04 June 2015 - 02:41 PM
Updated pastebin with zippy version 0.6-rc1
This is near of a full rewrite of the (de)compression code and hopefully the last breaking change to the archive format.
I would like to obtain a stable version 1 of the archive format before adding new features.
That way anyone could start using it without fear of data corruption/losses.
Any help to troubleshot this thing would be much appreciated.
Planned features:
- Nested archives
- Auto-extractible archives
- Interactive system backup maker
2679 posts
Location
You will never find me, muhahahahahaha
Posted 04 June 2015 - 03:19 PM
Or, have oit do something liken -except:rom;bla/ble/bleh;other/folder
673 posts
Posted 04 June 2015 - 05:23 PM
I made a program that turns a zippy archive into a self-extractor, are you proud of me? :P/>
http://pastebin.com/rV88JWtn made
http://pastebin.com/p0iE03YF
30 posts
Posted 04 June 2015 - 05:47 PM
Well, at least it's a start. ^_^/>
Hoperfully it's not required to embed zippy totally to make an auto-extracting archive.
Also please respect the code license.
The
MIT License is a
free software license originating at the
Massachusetts Institute of Technology (MIT).
[1] It is a
permissive free software license, meaning that it permits reuse within
proprietary software provided all copies of the licensed software include a copy of the MIT License terms and the copyright notice.

1140 posts
Location
Kaunas, Lithuania
Posted 04 June 2015 - 06:14 PM
Planned features:
*Nested archives
I'd suggest you to just add full binary support, rather than
specific binary files.
Edited on 04 June 2015 - 04:14 PM
673 posts
Posted 04 June 2015 - 06:18 PM
Well, at least it's a start. ^_^/>
Hoperfully it's not required to embed zippy totally to make an auto-extracting archive.
Probably not, I coded that in about 10 minutes :P/>
You could import it from the web if you wanted, but of course you'd have to save the file before extracting it, which I aimed not to do.
Also please respect the code license.
Done
EDIT: Updated ZSF to v1.1, now gets API from the web (also loads the "zippy" file if given client-side)
EDIT 2: Updated ZSF to v1.2, chance of nested multi-line strings breaking the self-extractor is now very low
Edited on 04 June 2015 - 06:48 PM
30 posts
Posted 04 June 2015 - 07:28 PM
I'd suggest you to just add full binary support, rather than specific binary files.
You're absolutly right! Not sure if its for v1 or v2 though.
Also please respect the code license.
Done
Thanks.
I see you use zsf file extension for auto-extractible archive which I'm fine with.
What about the "simple" zippy archive file extension… zyp?
Or is it even needed since file recognition is base on specific header string?
673 posts
Posted 04 June 2015 - 08:22 PM
I see you use zsf file extension for auto-extractible archive which I'm fine with.
"Zippy Self (extracting) File"
What about the "simple" zippy archive file extension… zyp?
Chances are ZSF will be different from ZYP, and either way it isn't implemented yet, so right now I'm content with ZSF.
Or is it even needed since file recognition is base on specific header string?
Why is ".png" needed? All png files start with "‰PNG".
Why is ".jpg" needed? All jpeg files start with

It's preferable just so you can tell you have to use zippy to extract it without opening the file, and it's easier for operating systems to handle because they don't have to open the file to tell if it's a zippy file, they can just glance at it's name.
Same goes for .zsf files; all .zsf files start with

where v1.2 is replaced with the ZSF version used to compile it, but it's still easier to glance at the file's name rather than reading the first 3 lines of the program.
Edited on 04 June 2015 - 06:51 PM