
1715 posts
Location
ACDC Town
Posted 30 July 2016 - 01:45 AM
After looking at Depman by CloudNinja, I figured "Hey, I've never tried this before." Why not give it a go?
Programmed over the course of about an hour, I give you…
PROGDOR
Burninating the competition since 2006
pastebin get YXx5jjMV progdor
std ld progdor progdor
Use progdor on a folder, and it will turn it into a file (defaultly by the same name)
Use progdor on that same file, and it will turn back into a folder (also defaultly by that same name)
Compression using CCA is enabled by default, but can be disabled by changing the 'doCompress' to false.
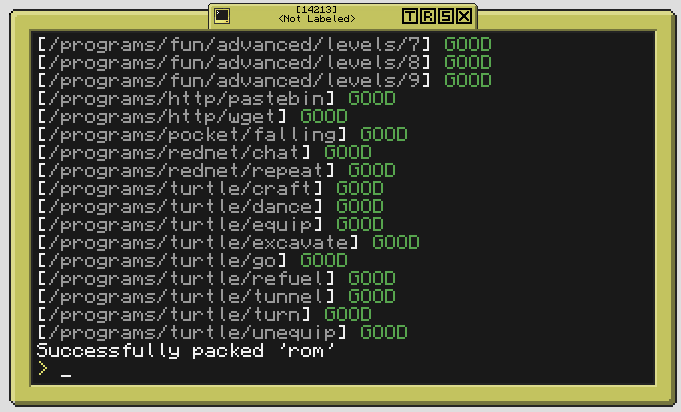
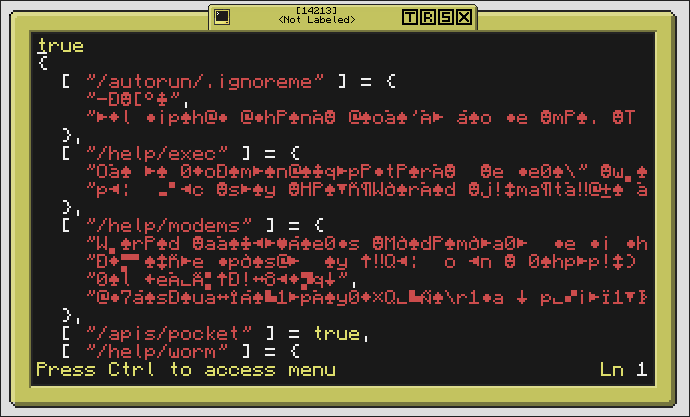
Screenshots:
Spoiler
Packaged '/rom' into '/the_rom'
Contents of 'the_rom', because it's compressed (if it's 'true', then it's an empty folder)
Edited on 05 August 2016 - 05:43 AM

135 posts
Posted 30 July 2016 - 09:12 AM
There is no compression, because that is hard. Forget about encryption. It does support empty folders, though, so that's something.
there is a simple solution for compressing, replace all spaces with byte(0) its a little smaller than byte(32) :)/>
Lol, i have started learning Assembly and stuff and now i realize what Lignum said. As 0 is still interpreted as an ASCII (8bit char) by computercraft.
Edited on 23 September 2016 - 12:00 AM

570 posts
Posted 30 July 2016 - 12:37 PM
there is a simple solution for compressing, replace all spaces with byte(0) its a little smaller than byte(32) :)/>
No it's not, a byte takes up 1 byte no matter what value it bears.
1715 posts
Location
ACDC Town
Posted 30 July 2016 - 06:50 PM
I don't see compression as completely necessary, but if I find an easy compression API, I'll be sure to try to implement it. As long as it's lossless. Like, doesn't remove whitespace or something.
143 posts
Location
Palm Bay, Florida
Posted 30 July 2016 - 09:22 PM
Why not take a look at the functions from CCA? (LZW compression w/ clear code) you'd simply copy the first 127 lines, then call compress (string to compress) which returns a table of bytes. Call decompress(table of bytes) to decompress.
(Also shameless self advertising)
Edited on 30 July 2016 - 07:25 PM
1715 posts
Location
ACDC Town
Posted 31 July 2016 - 07:46 PM
I tried CCA, failed, gave up, then realized what I might've done wrong just now.
You may see CCA in the next update. I'll have to include some metadata in packages, however. I can work that out.
This also assumes that CCA has a good enough compression ratio to bother with.
1715 posts
Location
ACDC Town
Posted 31 July 2016 - 09:28 PM
An update!
I have added CCA compression to PROGDOR! Due to the changes, if you packaged a folder with a previous version, you'll need to add a line reading "false" to the top of the file, so that PROGDOR knows it's not compressed.
By the way, compression is toggled with a local variable called 'doCompress'. If true, it compresses. Regardless, if a package is compressed and doCompress = false, it will still decompress because it is cool like that.
EDIT:
Apparently textutils.serialize() would turn certain special characters into an escape sequence, so I quickly added a function to fix that when writing files.
Edited on 31 July 2016 - 08:51 PM

18 posts
Location
Star System Sol, Galactic Sector ZZ9 Plural Z Alpha
Posted 01 August 2016 - 07:17 PM
Encryption isn't that hard too, there are like 3 AES APIs out there. A good one is by SquidDev (
Topic).
1715 posts
Location
ACDC Town
Posted 01 August 2016 - 07:40 PM
The problem isn't whether or not I could do it. It just doesn't seem that useful.
Another thing, is that Progdor doesn't like huge amounts of files. I don't know where to put that yield() function to prevent it from crashing, or worse, shutting down and outputting an empty file.
1715 posts
Location
ACDC Town
Posted 04 August 2016 - 05:04 AM
An update!
I found the problem as to why progdor crashes after compressing large amounts of files. After compressing, it would filter out any escape sequences that would crop up with a function called 'fixstr'. Turns out, that function was horribly inefficient. After looking up cryptic stuff with string.gsub(), I fixed that.
…and I added verbose output. With colors!
Still, if you put in a file that's way too big to compress, it'll crash. Thankfully, it won't delete anything.
Edited on 15 August 2016 - 06:10 PM

477 posts
Location
Germany
Posted 19 August 2016 - 07:57 AM
You could make it even better if you would make it only 1 string per file also you might want to look into modifying the serialization to not include the newlines and spaces.
1715 posts
Location
ACDC Town
Posted 20 August 2016 - 01:57 AM
You could make it even better if you would make it only 1 string per file also you might want to look into modifying the serialization to not include the newlines and spaces.
That's not possible, I don't think. Compressing a file adds newlines, and removing them might mess with it. Newlines are characters, too!
477 posts
Location
Germany
Posted 20 August 2016 - 08:21 AM
I know, but what i mean is this:
You store it like this currently:
{
["filename"] = {
"Line1",
"Line2"
}
}
Why don't you store it like this:
{
["filename"] = "Line1\nLine2"
}
You can just do
f = fs.open(file,"r")
files[file] = f.readAll()
f.close()

7083 posts
Location
Tasmania (AU)
Posted 20 August 2016 - 08:45 AM
FWIW, texutils.unserialise() can deal with strings such as "\"first line\\nsecond line\"" for you. Unfortunately I can't seem to get textutils.serialise() to create such strings - at least, not through Mimic.
(Remember, those functions can deal with objects other than tables!)
Though I'm not sure I see the need to avoid new line characters - I'm sure lots of different characters appear in the compression stream.
Edit:
Come to think of it, textutils.urlEncode() is probably what I was thinking of.
Edited on 20 August 2016 - 06:47 AM
1715 posts
Location
ACDC Town
Posted 20 August 2016 - 09:41 AM
You know, I just realized I could just use [[ and ]] for multiline strings. Why didn't I use them before…? I wonder if it'd mess with programs with multiline strings inside them.

8543 posts
Posted 20 August 2016 - 01:00 PM
You could examine the text looking for the maximum block quote level and then surround it with block quotes one level greater.
44 posts
Posted 20 August 2016 - 01:19 PM
If you used a binary file instead of a serialized table you could shorten it down alot more. For example, f.write(filename.."\0"..toBytes(file)..file) where toBytes returns a 4 byte string representing the filesize.
1715 posts
Location
ACDC Town
Posted 20 August 2016 - 07:18 PM
You could examine the text looking for the maximum block quote level and then surround it with block quotes one level greater.
That sounds complicated, and I'm a lazy bastard. I had a function that goes through the file to replace all instances of "\***" with string.char(***), and for big files, that takes far too long. I since replaced the code with a clever string.gsub(), but I'm supposing that code to analyze quote level will take too long for my purposes.
If you used a binary file instead of a serialized table you could shorten it down alot more. For example, f.write(filename.."\0"..toBytes(file)..file) where toBytes returns a 4 byte string representing the filesize.
That doesn't sound like a bad idea, but I'm not so sure that I could turn compressed files into binaries. And I don't think it preserves comments.
I know, but what i mean is this:
You store it like this currently:
{
["filename"] = {
"Line1",
"Line2"
}
}
Why don't you store it like this:
{
["filename"] = "Line1\nLine2"
}
You can just do
f = fs.open(file,"r")
files[file] = f.readAll()
f.close()
That IS a good idea. HMM…
8543 posts
Posted 20 August 2016 - 08:28 PM
Uhh,
local max = 0
for match in string.gmatch(fileContents, "%](=*)%]" do
max = math.max(max, #match)
end
local quotedContents = "["..string.rep("=", max + 1).."["..fileContents.."]"..string.rep("=", max + 1).."]"
Yeah, that's waaay too complicated.
1715 posts
Location
ACDC Town
Posted 20 August 2016 - 09:08 PM
Uhh,
local max = 0
for match in string.gmatch(fileContents, "%](=*)%]" do
max = math.max(max, #match)
end
local quotedContents = "["..string.rep("=", max + 1).."["..fileContents.."]"..string.rep("=", max + 1).."]"
Yeah, that's waaay too complicated.
…lazy bastard I am. Also, um, I've never touched the string.gmatch function, and didn't know you could do "for
match", so pooh pooh on me. Personally, I think the whole
string.gsub/gmatch patterns are complicated, and I never could remember them.
Lesson for today is to look at every Lua function ever. Anyway, I tried to replace all instances of "\n" with "\\n" so it could fit on one line, but…it didn't work. Looking in one of the files, I saw an instance of "\\n", when I expected "\n"…and I haven't the slightest idea why.
477 posts
Location
Germany
Posted 21 August 2016 - 09:44 AM
Uhh,
local max = 0
for match in string.gmatch(fileContents, "%](=*)%]" do
max = math.max(max, #match)
end
local quotedContents = "["..string.rep("=", max + 1).."["..fileContents.."]"..string.rep("=", max + 1).."]"
Yeah, that's waaay too complicated.
Even if you don't remove the newlines and stuff from serialization you could save a lot of space by saving a whole file into only one string, not into multiple strings(1 per line).
I asked someone who has a function to serialize something without the formatting if he has any problems with releasing it.